




GQLAlchemy query builder will help you build Cypher queries in no time! With this blog post, you will learn how to use different query builder methods to create, change, get, set, and remove data from Memgraph.
You can find the original Jupyter Notebook in our open-source GitHub repository.
Set everything up
If you want to try the code from this blog post, make sure to install Docker and GQLAlchemy. Docker is used because Memgraph is a native Linux application and can't be installed on Windows and macOS. After you install Docker, you can set up Memgraph by running:
docker run -it -p 7687:7687 -p 7444:7444 -p 3000:3000 memgraph/memgraph-platform:2.2.6
This command will start the download and after it finishes, run the Memgraph container.
We will be using the GQLAlchemy object graph mapper (OGM) to connect to Memgraph and execute Cypher queries easily. GQLAlchemy also serves as a Python driver/client for Memgraph. You can install it using:
pip install gqlalchemy==1.2.0
Hint: You may need to install CMake before installing GQLAlchemy.
from gqlalchemy import Memgraph
memgraph = Memgraph("127.0.0.1", 7687)
Make sure that Memgraph is empty before starting with anything else. Also, you should drop all indexes, if there are any, since you'll be creating new ones.
memgraph.drop_database()
memgraph.drop_indexes()
Define graph schema
You will create Python classes that will represent the graph schema. This way, all the objects that are returned from Memgraph will be of the correct type if the class definition can be found. That is not a part of the query builder, but it will help you work with the nodes and relationships.
from typing import Optional
from gqlalchemy import Node, Relationship, Field
class Movie(Node):
id: int = Field(index=True, unique=True, exists=True, db=memgraph)
title: Optional[str]
class User(Node):
id: int = Field(index=True, unique=True, exists=True, db=memgraph)
name: Optional[str]
class Rated(Relationship, type="RATED"):
rating: float
Create nodes and relationships
To return all the variables from a query, just use the return_() method at the
end of your query. Don't forget to execute() each query. First, you can create
some users in the database:
from gqlalchemy import create
ron = next(create().node(labels="User", id=0, name="Ron", variable="ron").return_().execute())
john = next(create().node(labels="User", id=1, name="John", variable="john").return_().execute())
maria = next(create().node(labels="User", id=2, name="Maria", variable="maria").return_().execute())
jenny = next(create().node(labels="User", id=3, name="Jenny", variable="jenny").return_().execute())
ian = next(create().node(labels="User", id=4, name="Ian", variable="ian").return_().execute())
users = [ron, john, maria, jenny, ian]
for user in users:
print(user)
Output:
{'ron': <User id=0 labels={'User'} properties={'id': 0, 'name': 'Ron'}>}
{'john': <User id=1 labels={'User'} properties={'id': 1, 'name': 'John'}>}
{'maria': <User id=2 labels={'User'} properties={'id': 2, 'name': 'Maria'}>}
{'jenny': <User id=3 labels={'User'} properties={'id': 3, 'name': 'Jenny'}>}
{'ian': <User id=4 labels={'User'} properties={'id': 4, 'name': 'Ian'}>}
Next, create a couple of movies:
lotr = next(create().node(labels="Movie", id=0, title="LOTR", variable="lotr").return_().execute())
home_alone = next(create().node(labels="Movie", id=1, title="Home Alone", variable="home_alone").return_().execute())
star_wars = next(create().node(labels="Movie", id=2, title="Star Wars", variable="star_wars").return_().execute())
hobbit = next(create().node(labels="Movie", id=3, title="Hobbit", variable="hobbit").return_().execute())
matrix = next(create().node(labels="Movie", id=4, title="Matrix", variable="matrix").return_().execute())
movies = [lotr, home_alone, star_wars, hobbit, matrix]
for movie in movies:
print(movie)
Output:
{'lotr': <Movie id=5 labels={'Movie'} properties={'id': 0, 'title': 'LOTR'}>}
{'home_alone': <Movie id=6 labels={'Movie'} properties={'id': 1, 'title': 'Home Alone'}>}
{'star_wars': <Movie id=7 labels={'Movie'} properties={'id': 2, 'title': 'Star Wars'}>}
{'hobbit': <Movie id=8 labels={'Movie'} properties={'id': 3, 'title': 'Hobbit'}>}
{'matrix': <Movie id=9 labels={'Movie'} properties={'id': 4, 'title': 'Matrix'}>}
Now you need to connect users and movies with the RATED relationship:
from gqlalchemy import match
match().node(labels="User", id=0, variable="u").match().node(labels="Movie", id=0, variable="m").create().node(variable="u").to(edge_label="RATED", rating=5.0).node(variable="m").execute()
match().node(labels="User", id=0, variable="u").match().node(labels="Movie", id=1, variable="m").create().node(variable="u").to(edge_label="RATED", rating=3.2).node(variable="m").execute()
match().node(labels="User", id=0, variable="u").match().node(labels="Movie", id=2, variable="m").create().node(variable="u").to(edge_label="RATED", rating=4.3).node(variable="m").execute()
match().node(labels="User", id=1, variable="u").match().node(labels="Movie", id=0, variable="m").create().node(variable="u").to(edge_label="RATED", rating=5.0).node(variable="m").execute()
match().node(labels="User", id=2, variable="u").match().node(labels="Movie", id=0, variable="m").create().node(variable="u").to(edge_label="RATED", rating=4.9).node(variable="m").execute()
match().node(labels="User", id=3, variable="u").match().node(labels="Movie", id=3, variable="m").create().node(variable="u").to(edge_label="RATED", rating=2.3).node(variable="m").execute()
match().node(labels="User", id=3, variable="u").match().node(labels="Movie", id=4, variable="m").create().node(variable="u").to(edge_label="RATED", rating=4.8).node(variable="m").execute()
match().node(labels="User", id=4, variable="u").match().node(labels="Movie", id=0, variable="m").create().node(variable="u").to(edge_label="RATED", rating=4.0).node(variable="m").execute()
To check whether the data is correctly imported into Memgraph, you can open
Memgraph Lab on localhost:3000.
In the query editor, run:
MATCH (u)-[r]->(m)
RETURN u, r, m;
You'll see the imported data visualized as a graph below:
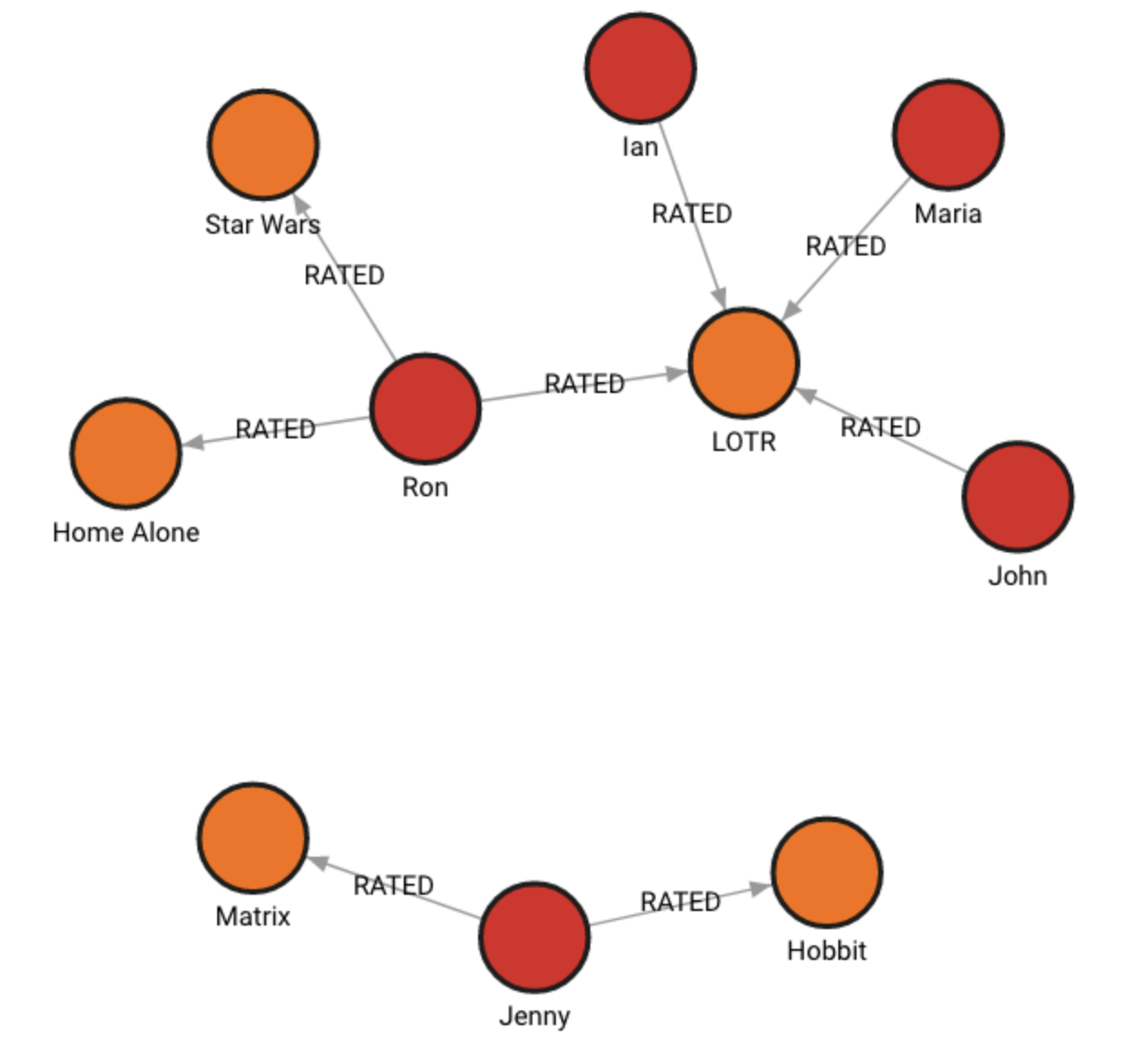
Filter results
You can filter data by comparing the property of a graph object to a value
(a literal). To return only a subset of variables from a query, specify them in
the return() method. Below you can see how to compare name and title
properties of nodes to a string value.
results = list(match()
.node(labels="User", variable="u")
.to(edge_label="RATED")
.node(labels="Movie", variable="m")
.where(item="u.name", operator="=", literal="Maria")
.and_where(item="m.title", operator="=", literal="LOTR")
.return_({"u.id": "user_id", "m.id": "movie_id"})
.execute()
)
for result in results:
print("Maria's id:", result["user_id"])
print("LOTR id:", result["movie_id"])
Output:
Maria's id: 2
LOTR id: 0
You filtered the data by finding a user with name Maria, who rated the movie
with title LOTR.
You can also negate the expression in WHERE clause, using the where_not()
method. Similarly, you have and_not_where(), or_not_where() and
xor_not_where() methods.
results = list(match()
.node(labels="User", variable="u")
.to(edge_label="RATED")
.node(labels="Movie", variable="m")
.where_not(item="u.name", operator="=", literal="Maria")
.and_where(item="m.title", operator="=", literal="LOTR")
.return_({"u.name": "user_name"})
.execute()
)
for result in results:
print(result["user_name"])
Output:
Ron
John
Ian
What happened above? You filtered the data by finding the names of all users who are not Maria and who rated the movie LOTR.
You can also filter data by comparing properties of graph objects:
results = list(match()
.node(labels="User", name="Maria", variable="u")
.match()
.node(labels="User", variable="v")
.where(item="u.name", operator="!=", expression="v.name")
.return_({"v.name": "user_name"})
.execute()
)
for result in results:
print(result["user_name"])
Output:
Ron
John
Jenny
Ian
You found all the users that don't have the property name set to Maria.
Nodes can also be filtered by their label using the where() method instead
of specifying it directly in the node() method of the query builder. You have
to use expression as the third keyword argument since you want to escape the
quotes surrounding the label in the Cypher clause.
results = list(match()
.node(variable="u")
.where(item="u", operator=":", expression="Movie")
.return_()
.execute()
)
for result in results:
print(result)
Output:
{'u': <Movie id=5 labels={'Movie'} properties={'id': 0, 'title': 'LOTR'}>}
{'u': <Movie id=6 labels={'Movie'} properties={'id': 1, 'title': 'Home Alone'}>}
{'u': <Movie id=7 labels={'Movie'} properties={'id': 2, 'title': 'Star Wars'}>}
{'u': <Movie id=8 labels={'Movie'} properties={'id': 3, 'title': 'Hobbit'}>}
{'u': <Movie id=9 labels={'Movie'} properties={'id': 4, 'title': 'Matrix'}>}
Above you filtered all nodes in the database by the Movie label.
Call procedures
Let's see which movie is the most important in the network. You can suppose that
the most important movie will be the one that the largest number of users rated.
To order the returned results, use the order_by() method after the return_()
method.
from gqlalchemy import call
from gqlalchemy.query_builder import Order
results = list(call("pagerank.get")
.yield_()
.with_({"node": "node", "rank": "rank"})
.where(item="node", operator=":", expression="Movie")
.return_({"node.title": "movie_title", "rank": "rank"})
.order_by(properties=("rank", Order.DESC))
.execute()
)
for result in results:
print(result["movie_title"], result["rank"])
Output:
LOTR 0.26900584795321636
Hobbit 0.1
Matrix 0.1
Home Alone 0.09005847953216374
Star Wars 0.09005847953216374
Delete and remove objects
To delete a node from the database, use the delete() method:
match().node(labels="User", id=4, variable="u").delete(variable_expressions=["u"], detach=True).execute()
You deleted Ian from the database and the relationships he was connected with.
To delete a relationship from the database, again use the delete() method:
match().node(labels="User", id=0).to(edge_label="RATED", variable="r").node(labels="Movie", id=0).delete(variable_expressions=["r"]).execute()
Above you deleted the relationship between Ron and LOTR, that is, it seems like Ron hasn't rated LOTR.
To remove a property from the database, use the remove() method:
results = list(match()
.node(labels="User", name="Maria", variable="u")
.remove(items=["u.name"])
.return_()
.execute()
)
for result in results:
print(result)
Output:
{'u': <User id=2 labels={'User'} properties={'id': 2, 'name': None}>}
Now Maria's name is set to None, so you can only recognize her by the id
in the database.
What's next?
Now it's time for you to use Memgraph on a graph problem!
You can always check out Memgraph Playground for some cool use cases and examples. If you need some help with GQLAlchemy, join our Discord server and have a chat with us.
