

How to Write Custom Cypher Procedures With NetworkX and Memgraph

Introduction
NetworkX is a package for the creation, manipulation, and study of the dynamics, functions and structures of networks. It allows us to use complex graph algorithms to solve network-related problems.
Even though NetworkX is a very powerful and versatile package, it is somewhat limited in speed and efficiency because of its Python implementation and lack of quality storage. While this is not a problem with smaller data sets, in large networks this can be quite cumbersome. Using Memgraph, an in-memory graph database, as the storage solution provides additional benefits and functionalities to NetworkX.
In this post, we will focus on how to implement custom Cypher procedures using query modules and NetworkX. We will also discuss the open-source project MAGE where you can find already implemented modules and contribute your own.
Prerequisites
The prerequisites for this tutorial are either:
- Memgraph Platform: the complete streaming graph application platform that includes:
- MemgraphDB - the database that holds your data
- Memgraph Lab - an integrated development environment used to import data, develop, debug and profile database queries and visualize query results
- mgconsole - command-line interface for running queries
- MAGE - graph algorithms and modules library
or
- Memgraph Cloud: a hosted and fully-managed service that utilizes all Memgraph products such as MAGE and in-browser Memgraph Lab
Understanding NetworkX Basics
To fully utilize the power of graphs, you first need to get a basic understanding of the underlying concepts in graph theory and their corresponding terminology when working with the NetworkX package.
The four main types of graphs that you will see throughout this and other tutorials are:
- Graph - An undirected graph with self-loops.
- DiGraph - A directed graph with self-loops.
- MultiGraph - An undirected graph with self-loops and parallel edges.
- MultiDiGraph - A directed graph with self-loops and parallel edges.
A self-loop (also called a loop or a buckle) is an edge that connects a vertex to itself while parallel edges (also called multiple edges or a multi-edge) are two or more edges that are incident to the same two nodes.
Memgraph offers a comprehensive set of thin wrappers around most of the algorithms and objects present in the NetworkX package. The wrapper functions have the capability to create a NetworkX compatible graph-like object that can stream the native database graph directly saving on memory usage significantly. For example, the NetworkX class MultiDiGraph has a MemgraphMultiDiGraph wrapper while the DiGraph class uses the MemgraphDiGraph wrapper class.
Setting up NetworkX in Memgraph
Memgraph supports extending the query language with user-written procedures. These procedures are grouped into modules, and if written in Python, can be developed directly from Memgraph Lab. We are going to create such a procedure to work with the NetworkX package.
In Memgraph Lab, query modules are written in the Query modules section where you can also find built-in query modules that come prepackaged with Memgraph Platform and Cloud. To learn more about query modules check out the Memgraph documentation on the subject.
Writing a Custom Procedure for Cypher
First, we need a basic data set to start with. Let's create a very simple graph with two cities that are connected by a road.
The cities are nodes while the road is an edge connecting these nodes. Open Memgraph Lab and in the Query Execution section run the following query:
CREATE (c1:City { name: 'Boston' }), (c2:City { name: 'New York' })
CREATE (c1)-[r:ROAD_TO { distance: 100}]->(c2)
RETURN c1, c2, r;
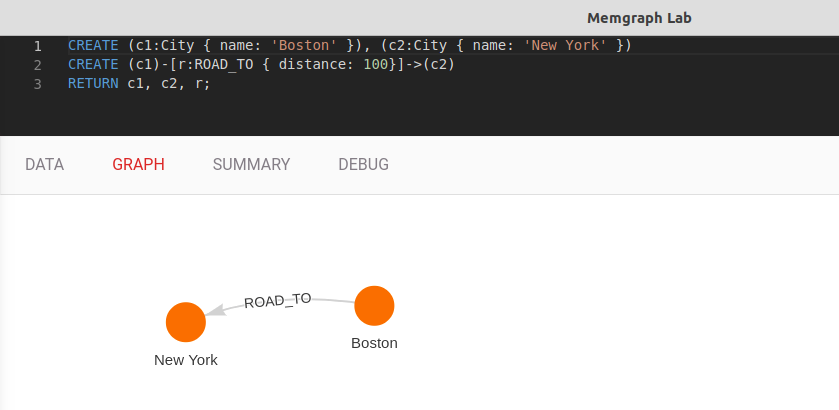
This has created two nodes with the label City and a name property.
The edge between them is of type ROAD_TO and has the property distance which represents the distance in kilometers.
We want a slightly more complex network to use with NetworkX so let's extend it with the following queries:
MATCH (c1:City { name: 'Boston' })
CREATE (c2:City { name: 'Philadelphia' }), (c3:City { name: 'Seatle' }), (c4:City { name: 'Los Angeles' }), (c5:City { name: 'San Francisco' })
CREATE (c1)-[:ROAD_TO { distance: 110}]->(c2)
CREATE (c3)-[:ROAD_TO { distance: 150}]->(c2)
CREATE (c4)-[:ROAD_TO { distance: 200}]->(c5)
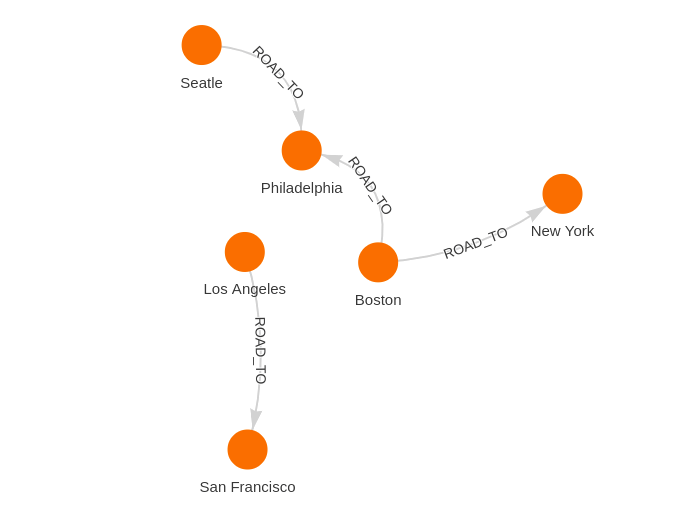
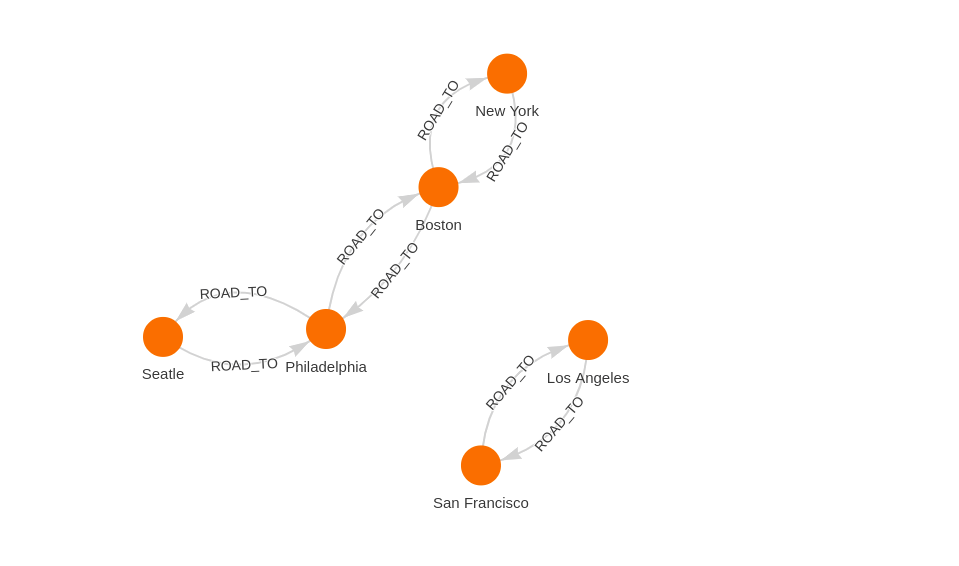
This is a simple directed graph and while using NetworkX it would be stored as a DiGraph. If we were to duplicate all the edges and reverse the direction of the duplicates, we would end up with a MultiDiGraph because of the parallel edges. This could be accomplished by the following query:
MATCH (c0:City { name: 'New York' }), (c1:City { name: 'Boston' }),
(c2:City { name: 'Philadelphia' }), (c3:City { name: 'Seatle' }),
(c4:City { name: 'Los Angeles' }), (c5:City { name: 'San Francisco' })
CREATE (c1)<-[:ROAD_TO { distance: 100}]-(c0)
CREATE (c1)<-[:ROAD_TO { distance: 110}]-(c2)
CREATE (c3)<-[:ROAD_TO { distance: 150}]-(c2)
CREATE (c4)<-[:ROAD_TO { distance: 200}]-(c5)
Now, let's play with our graph in NetworkX. Open the Query modules section and click on the + New Module. Give the modules name hello_world. A new query module will be created with example procedures. Feel free to erase them and copy the following code into it:
import mgp
import networkx as nx
from mgp_networkx import (MemgraphMultiDiGraph, MemgraphDiGraph,
MemgraphMultiGraph, MemgraphGraph,
PropertiesDictionary)
@mgp.read_proc
def procedure(ctx: mgp.ProcCtx) -> mgp.Record(nodes=mgp.List[mgp.Vertex]):
g = MemgraphMultiDiGraph(ctx=ctx)
return mgp.Record(nodes=list(g.nodes()))
The first three lines are basic Python imports which all of our query modules that utilize NetworkX need to have.
Because we are working with data stored in Memgraph, a wrapper is used to reference the stored graph. The line g = MemgraphMultiDiGraph(ctx=ctx) implies that we are creating this reference from the current context ctx (automatically passed in all procedure calls) and it represents a nx.MultiDiGraph class.
The procedure returns a list of nodes from the graph. If you need a more detailed understanding of the custom objects and wrappers take a look at the query modules Reference Guide.
Save and close the window then move to the Query Execution section to use the procedure.
Call the procedure to return results:
CALL hello_world.procedure() YIELD nodes RETURN nodes;
What we get is a list of nodes in the graph.
Let's change the procedure to also return the number of nodes and the number of edges in the graph. Go back to the Query Modules section, find the hello_world query module, click on the arrow on the right to see its details, then edit it by modifying the code:
@mgp.read_proc
def procedure(ctx: mgp.ProcCtx) -> mgp.Record(nodes=mgp.List[mgp.Vertex],
number_of_nodes=int,
number_of_edges=int):
g = MemgraphMultiDiGraph(ctx=ctx)
list_of_nodes = list(g.nodes())
num_of_nodes = g.number_of_nodes()
num_of_edges = g.number_of_edges()
return mgp.Record(nodes=list_of_nodes,
number_of_nodes=num_of_nodes,
number_of_edges=num_of_edges)
Before you calling the procedure, don't forget to save the module.
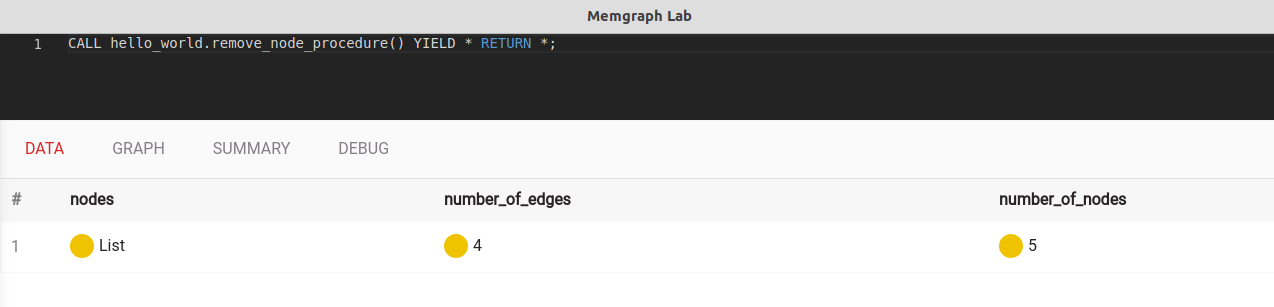
CALL mg.load_all();
CALL hello_world.procedure() YIELD * RETURN *;
With YIELD * we make sure that the procedure returns all of the results and by using RETURN * we print them all out.
Editing Graphs with NetworkX
It's important to note that you can't do any database write operations directly from a query module. Otherwise, it wouldn't be possible to guarantee the integrity of the database. You can however save the whole graph or just a subgraph as a completely new object and then perform edits before returning the results. Let's say we wanted to find out what our custom procedure would return if we removed the cities Boston and New York from our network. Create a new procedure in the same module and name it remove_node_procedure():
@mgp.read_proc
def remove_node_procedure(ctx: mgp.ProcCtx) -> mgp.Record(nodes=mgp.List[mgp.Vertex],
number_of_nodes=int):
g = MemgraphMultiDiGraph(ctx=ctx)
g_copy = nx.MultiDiGraph(g)
for node in list(g_copy.nodes):
if node.properties.get('name') == 'Boston':
g_copy.remove_node(node)
list_of_nodes = list(g_copy.nodes)
num_of_nodes = g_copy.number_of_nodes()
return mgp.Record(nodes=list_of_nodes,
number_of_nodes=num_of_nodes)
As you can see, the returned list does not contain the city Boston.
Passing Arguments to Custom Procedures
Let's make a new procedure that uses the nx.is_simple_path() algorithm. A simple path in a graph is a nonempty sequence of nodes in which no node appears more than once in the sequence, and each adjacent pair of nodes in the sequence is adjacent in the graph. The simple_path_procedure() could look like this:
@mgp.read_proc
def simple_path_procedure(ctx: mgp.ProcCtx, nodes: mgp.List[mgp.Vertex]
) -> mgp.Record(is_simple_path=bool):
g = MemgraphMultiDiGraph(ctx=ctx)
simple_path = nx.is_simple_path(g, nodes)
return mgp.Record(is_simple_path=simple_path)
You can call the procedure by executing the following query from Memgraph Lab:
MATCH p=((c1:City {name:'Boston'})-[:ROAD_TO]->(c2:City {name:'New York'}))
CALL hello_world.simple_path_procedure(nodes(p)) YIELD is_simple_path RETURN is_simple_path;
With this query, we have created a list of nodes from the path Boston--New York and the simple_path_procedure() should return True because it is a simple path.
MAGE - Introducing Memgraph Advanced Graph Extensions
MAGE is an open-source repository provided by Memgraph that contains implementations of query modules, written by our engineers or contributed by the developer community.
In it, you can find implementations of various algorithms in multiple programming languages, all runnable inside Memgraph. Some of the available algorithms and problems that are tackled with MAGE include PageRank, Weakly Connected Components (Union Find), Jaccard similarity coefficient, Travelling Salesman Problem... and many more.
Don't hesitate to contribute any custom modules you come up with if you think they would be of help to fellow developers. We would be more than happy to take a look and add them to the repository.
Conclusion and Next Steps
While there are some limited functionalities, Memgraph offers a straightforward way of using the NetworkX package on graph-like objects that can stream the native database graph directly. This kind of implementation improves memory usage significantly and adds in-memory efficiency to NetworkX algorithms.
For a more in-depth explanation of how to create your own custom Cypher procedures take a look at our How to Implement Query Modules? guide or go through the already implemented algorithms in MAGE.




